
Sqoop Incremental Load Failed Without Job
In this post, big data consulting company experts are performing incremental load with Sqoop in hadoop. They will explain why creating a job is important to implement this activity through this article. Read it thoroughly and understand.
Big Data framework is seasoning and adoption is gradually increasing. Big data framework isn't actually a framework at all. It's a community of software and hardware products -- at different levels of maturity -- that are enabling users to deal with:
- The fast growth of data
- Altogether New data types (such as sensor data)
- Complex streaming data such as video)
- The increased need to exploit data in real time to aid decision making and gain new levels of insight
Technology:
When we talk about streaming data in Hadoop ecosystem, there are various tools to support it, to name a few are Storm, Flume, Spark Streaming integrating with Kafka etc..But when we have to deal with the streaming data in batch mode or we can say incremental load in HDFS, then we need to look upon Sqoop with the ray of light.
With the continous addition/modification been implemented in Hadoop ecosytem, there comes a way to handle incremental load in HDFS from RDBMS with the help of Sqoop but there are still few limitations which we need to digest when dealing with incremental load, which is discussed below.
Use-case:
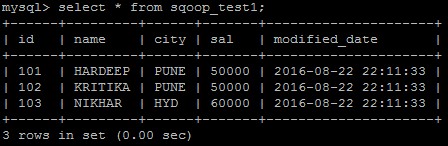
Below is the sample data in MySQL, which we will use to dump into HDFS.

Please see the timestamp below, which is the key factor in incremental load by determining the updated/new records.
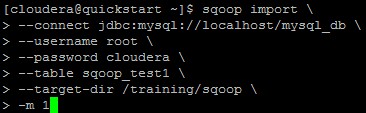
We will use basic Sqoop command which describes source table in MySQL and destination directory In HDFS.
We will run this command from CLI which will load the data into /training/sqoop from sqoop_test1.
After the command ran successful, we have looked into HDFS directory and we got the desired result.

Now we will update 2 of the rows in our base MySQL table and add 1 row into it as described below.
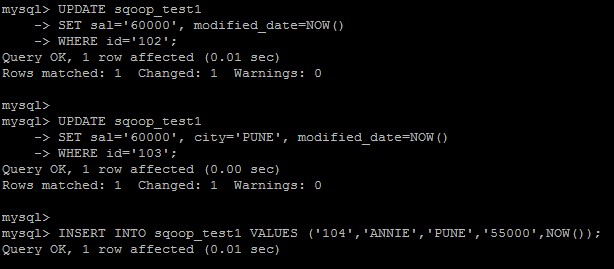
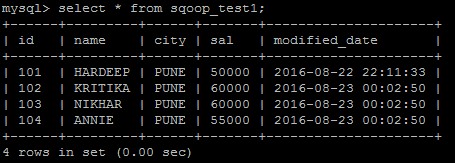
Verify the same that records has been successfully added and updated in MySQL table. Please note the new timestamps in records with id =102, 103, 104.
Issue:
After the successfully addition/updating of records in MySQL table, we will run Sqoop query for incremental load with the check column, incremental lastmodified and last value as an options.
If we have to perform incremental load in a regular manner, then we need to give last value option as a clause which will pick the timestamp automatically and don’t need to provide hardcode value each time.
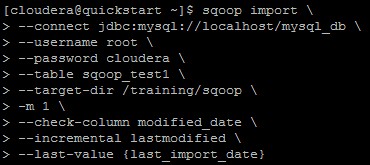
As soon as we submit the command, it throws error. We thought that we have missed to give few of the options so we have tried with append as an option. If one can’t able to see the error in below screen shot, then please refer to the box below the screenshot.

16/08/23 00:16:03 ERROR tool.ImportTool: Error during import: --merge-key or --append is required when using --incremental lastmodified and the output directory exists.
Submit the same Sqoop command with the append option as below.
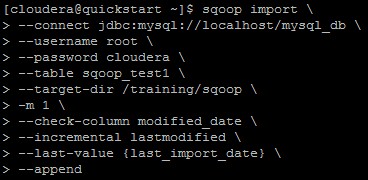
As we can see in below screenshot, it has taken last value timestamp as current value and not the actual last value in which we have implemented the load and hence we didn’t get any output in output directory.

We can see in the below screenshot that we received 0 bytes while fetching data from MySQL table.

Resolution:
Create a job with name incjob1 with the merge-key as a clause as mentioned in below screenshot.
Reason behind creating a job is that, job will save the last modified time in its memory which helps in fetching the records next time.
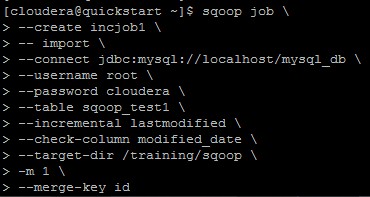
Submit the job with below command.

We can see the output in the file as below.

Now again we will update one record and add one record, please not the timestamp for the same.
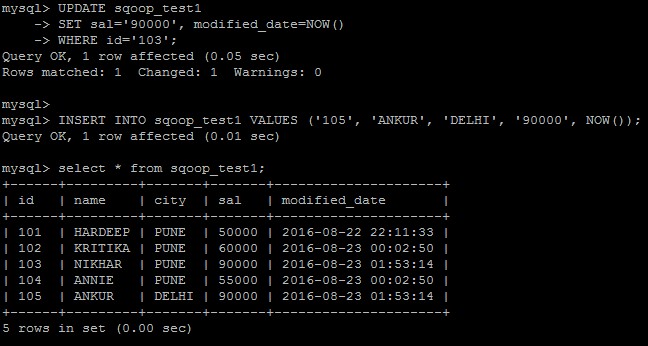
Delete the above created file and the again submit the job.
SUCCESS!!!
Below is the file in which we will get only updated record and newly added record.

Big data consulting company experts have explained the significance of creating a job to implement incremental load in Hadoop. If you still have query in your mind, ask freely through comments.
Conclusion:
While performing incremental load in Hadoop via Sqoop, always make a habit to implement this activity with creating a job this will help the Sqoop in saving the last value of timestamp in memory and you will get the desired result.